
刷到秋芝博主发布的“听播客辨真人/AI”视频时,我原本只是抱着“看热闹”的心态,想测测自己能否分辨出真人与AI之间的差别。然而听完那几段播客,尤其是其中一段包含笑声、语气起伏甚至“咽口水”等细节的AI音频后,我彻底震惊了:这竟然是AI生成的?就连“川渝说唱指南”里那种方言模仿的腔调,都像是真人主播在与你闲聊,彻底颠覆了我对“AI声音=机械生硬”的刻板印象。

怀着“非试不可”的好奇心,我立刻点开了火山引擎控制台,直奔豆包播客大模型页面。

然而,打开开发文档后第一眼看到的,就是一行醒目的提示:“该模型目前仅支持企业认证客户接入,暂不支持个人用户。”但这可难不倒我(此处略去操作流程)。我直接下载了Python SDK,用代码调起模型,如图所示:
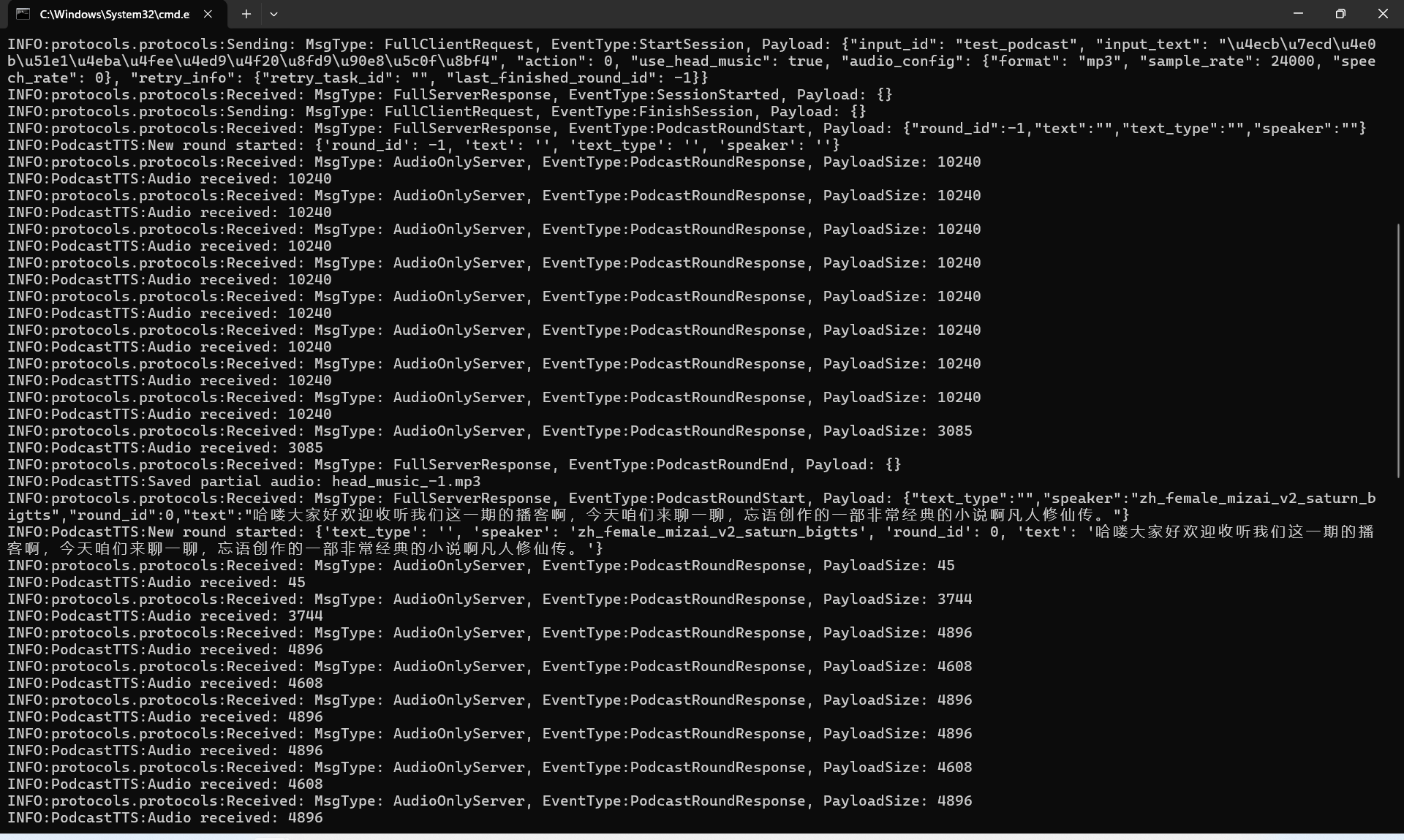

最终生成的播客音频质量令人惊喜。它不仅具备口播内容的典型特征,还自然地加入了停顿、语调变化,甚至模拟了问答环节,仿佛一位真实主播在娓娓道来。
<audio controls autoplay>
<source src="https://www.gosql.cn/uploads/audios/2025/08/20250824082711_68aa5c5f27a89.mp3" type="audio/mpeg">
您的浏览器不支持音频播放。
</audio>
下面是官方的SDK代码,有兴趣的同学可以学习下:
[<i class="fas fa-file text-secondary"></i> volcengine.speech.volc_speech_python_sdk_1.0.0.20.tar.gz](https://www.gosql.cn/uploads/attachments/2025/08/20250824083442_68aa5e2251917.gz)
