1、父子索引 补充深挖
子块粒度200~500token,父块 800~1500token
检索只查子向量库,召回相关子 chunk 后,批量关联父 chunk
优势:子块召回准、父块语义完整,避免短句检索上下文断裂
缺点:冗余 token 变多,需要配合上下文截断、去重
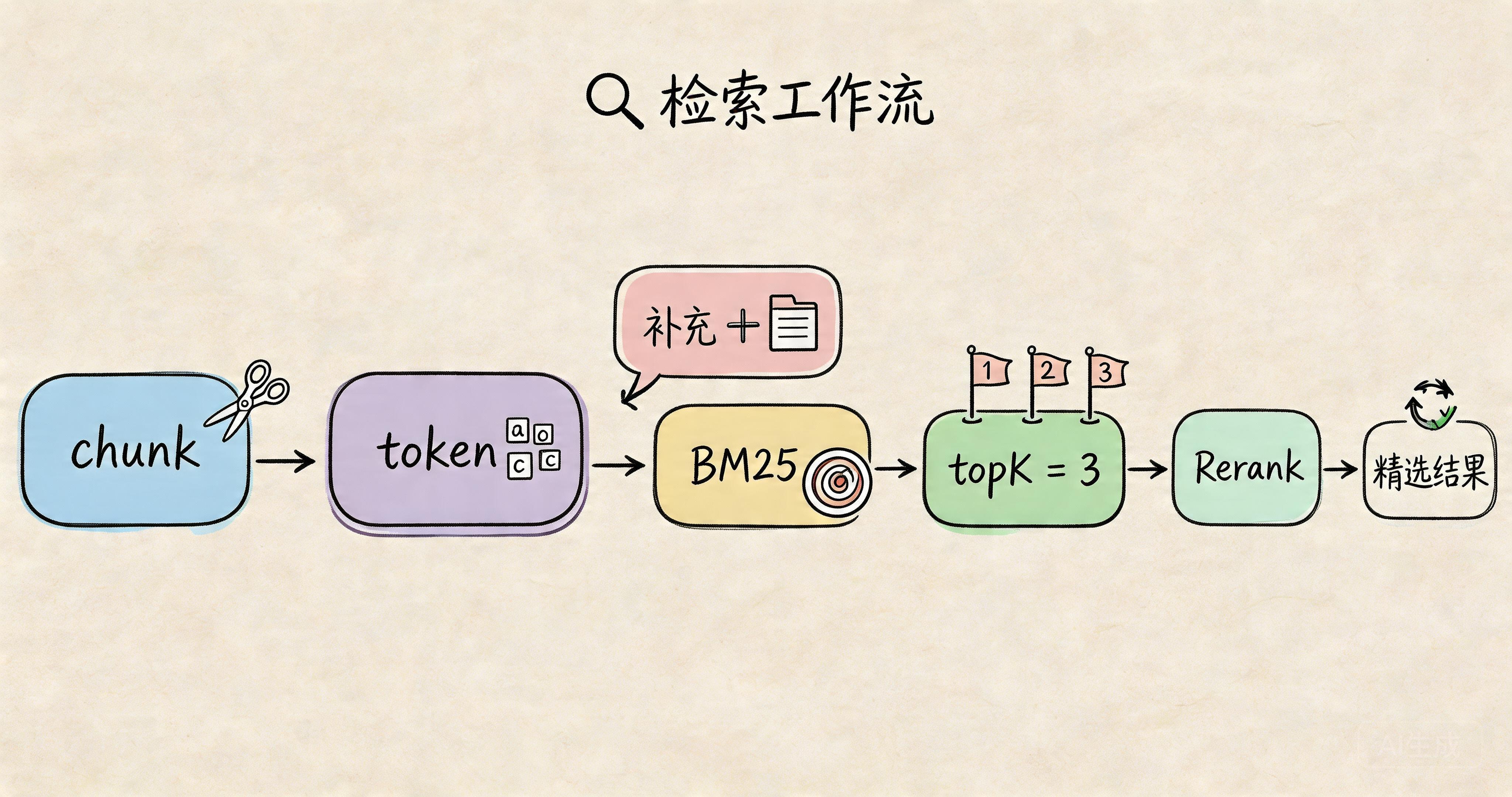
2、BM25 补充
BM25 基于词频 + 逆文档频率 TF-IDF 改良,抑制高频无用词权重
向量检索擅长同义改写,BM25 擅长专有名词、编号、型号、数字、法条
快手知识库大量业务名词、流水、编号,必须 BM25 兜底,否则大量漏召回
3、Rerank topK 补充
线上通用:初筛 top20~top30,rerank 后保留 top3~top8
超长文档 Agent:top10~12,严格卡模型上下文窗口 token 上限
4、TopK 截断 补充策略
硬截断:固定 N 条
分数阈值截断:相似度<0.6 直接丢弃
Token 总量截断:累加 chunk 总 token,超过模型最大上下文立刻停止
关联截断:同一个父文档只保留最优子块,不重复堆叠同源片段
5、上下文工程 进阶设计
分层上下文:系统指令层、对话历史层、知识库层、工具返回层
时序排序:严格按照对话时间顺序拼接,不打乱轮次
上下文优先级:新知识>最新对话>历史旧对话
冗余压缩:长对话摘要、重复问答合并、无效闲聊丢弃
格式隔离:用特殊分隔符严格区分用户输入 & 知识库内容
6、Agent 记忆机制 快手常用方案
短期记忆:对话滑动窗口,轮次限制 5~10 轮
中期记忆:单会话关键事件摘要持久化 Redis
长期记忆:用户画像、偏好、高频问题向量入库,对话触发召回
记忆淘汰:超时清理、低价值遗忘、重复记忆合并归一
7、Function Calling 完整流程
系统 Prompt 定义工具 schema、入参约束、异常返回格式
LLM 意图判断:是否调用→选哪个工具
结构化输出标准 JSON,不允许自由文本
后端参数校验、格式校验、权限校验
执行接口,拿到结果回填上下文
模型解析结果,判断是否二次多轮调用,直到任务结束
8、Agent 任务规划 快手常用架构
Planner 规划器 + Executor 执行器 + Reflect 反思器
用户复杂 query 拆解多子步骤
判断步骤依赖,串行 / 并行执行
单步失败:重试、换工具、回退步骤
结果校验不通过,反思修正重新规划
CoT 思维链引导分步推理,避免一步乱答
9、Prompt 注入防御 完整版
输入预处理:过滤越狱指令、分隔符、角色篡改话术
指令强隔离:系统 prompt 与用户输入物理分隔,不可覆盖
输出格式强约束,禁止模型复述系统指令
敏感意图拦截,拒绝角色扮演、指令覆盖请求
知识库内容与用户输入分开标记,防止混淆上下文
10、工具调用安全控制
接口权限最小化,禁止跨业务高危调用
调用频次、单次工具调用次数上限限制
SQL 类工具防注入,参数白名单校验
敏感操作二次确认、高危行为告警
工具返回结果清洗脱敏后再送入大模型
11、分布式令牌桶
Redis Lua 原子脚本实现,保证集群令牌增减原子性
桶容量 = 峰值流量,令牌生成速率 = 平稳 QPS
支持突发流量,不会像漏桶一样卡死
时间戳矫正,解决分布式节点时钟不一致问题
12、漏桶算法
不管流入流量多杂乱,流出速率恒定
强限流、流量绝对平滑
无法应对突发业务流量,接口响应差
不适合问答、Agent 高并发突发场景
13、滑动窗口
Redis 按秒 / 分钟分片存储请求计数
当前窗口 = 最近 N 个时间片总和
时间前进,淘汰过期分片
分布式高精度限流,但窗口越小 Redis 占用越高
14、滑动窗口 VS 令牌桶
令牌桶允许突发流量,滑动窗口严格平滑
令牌桶实现简单、性能高;滑动窗口精度高、开销大
滑动窗口临界边界存在统计误差,令牌桶无误差
Agent 接口突发多,快手优先分布式令牌桶
15、布隆过滤器
多个 Hash 函数映射到位图
不存在:100% 准确
存在:存在误判率
场景:缓存穿透、URL 去重、海量 ID 快速判存
缺点:无法删除元素,只能重建
16、MySQL 索引失效全场景
字段加减乘除、函数运算
字符串隐式类型转换
联合索引不满足最左前缀
or 包含非索引字段
not in、!=、is not null
大范围模糊 like
优化器认为回表代价>全表扫描,主动放弃索引
17、like 查询
like '前缀%' 走索引
like '%后缀' / '%中间%' 索引失效
长尾模糊查询可用全文索引、ES 检索替代
18、RAG 系统完整评测
离线自动评测 + 人工灰度评测 + 线上 Badcase 回流
检索链路指标
生成链路指标
端到端问答效果
耗时、并发、稳定性压测
19、完整评测维度
检索:Precision、Recall、MRR、NDCG、召回命中率
生成:事实准确率、幻觉率、引用一致性、逻辑通顺
对话:多轮连贯性、上下文不混乱、记忆准确
性能:首包耗时、平均耗时、并发承载
安全:注入抵御、敏感泄露、违规内容
20、评测数据集构成
标准 FAQ 问答对
歧义问题、跨文档综合问题
相似易混淆干扰问题
长尾冷门专业问题
Prompt 注入、恶意诱导问题
多轮上下文对话样本
负样本干扰文档
21、提升检索相关度
优化 chunk 切片长短、父子结构
领域微调 Embedding 向量模型
BM25 & 向量权重动态调参
高质量垂类 Rerank 模型
知识库清洗、归一化、去重降噪
同义词、实体别名归一
22、优化回答效果全思路
精炼 Prompt,强约束幻觉,强制溯源引用
减少无关上下文噪音,高质量 rerank
上下文压缩摘要,避免 token 拥挤错乱
领域 SFT 微调大模型
多文档交叉事实校验
Agent 反思校验机制
规范输出格式,拒绝编造信息
23、1000 条数据求和
单机:流式分批读取,避免 OOM,循环累加
并发:分片并行计算,最后汇总结果
数据库:直接 SUM 聚合,数据库底层优化
大数据:MapReduce 分片计算
处理:过滤空值、异常脏数据、精度保留
24、RAG 全链路性能优化
切片结构化 + 父子索引,向量库加速检索
混合检索 + 轻量 rerank,减少上下文 token
热点问答 Redis 缓存
KV Cache、模型量化推理加速
异步并行检索 + 工具调用
分布式向量集群扩容
长上下文蒸馏、上下文压缩
25、上下文完整处理流程
拼接顺序:系统指令 → 历史对话 → 检索知识片段 → 当前用户问题
Token 实时统计,超限滑动淘汰最早对话
重复 chunk 去重、低相关片段剔除
对话轮次标记,时序不乱序
特殊分隔符隔离模块,防止上下文混淆幻觉
