# BM25:工业级全文检索相关性打分基石
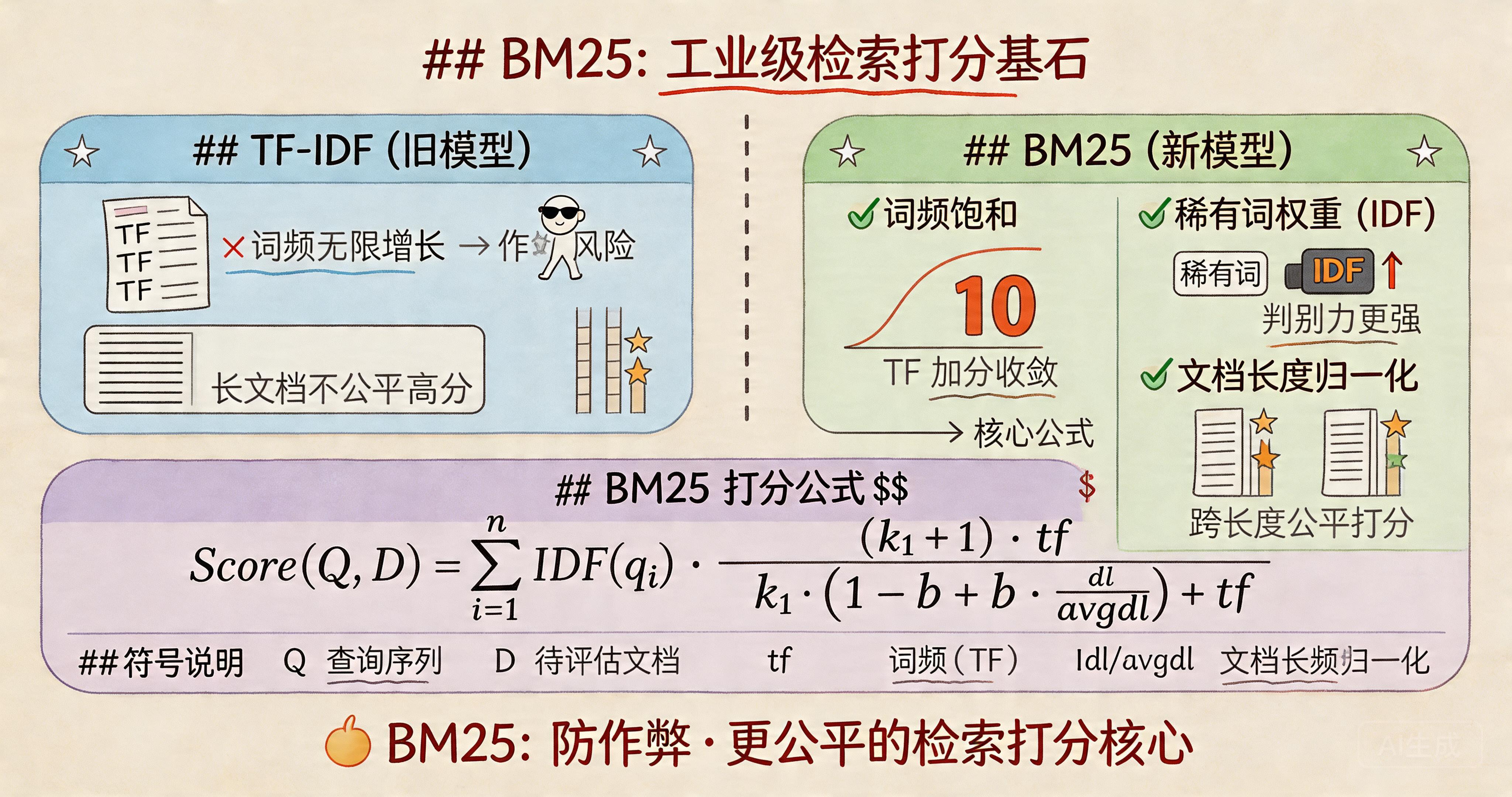
BM25 是一种基于概率排序框架的经典信息检索模型,也是 Elasticsearch 等主流搜索引擎的默认召回打分算法。它精准量化查询 $ Q $ 与文档 $ D $ 的语义相关性,驱动高效、公平、鲁棒的文档排序。相较于传统 TF-IDF,BM25 系统性地攻克了两大核心缺陷:**词频无限线性增长导致的作弊风险**,以及**长文档因长度优势获得不公平高分**的问题。
---
## 一、核心思想
- ✅ **词频饱和机制**:词在文档中出现越多,相关性越高;但加分趋于收敛,不会无限放大
- ✅ **稀有词高权重(IDF)**:在全库中覆盖文档越少的词,判别力越强,IDF 值越高
- ✅ **文档长度归一化**:相同词频下,短文档更相关;长文档自动降权,实现跨长度公平比较
- ⚠️ **纯词袋模型(Bag-of-Words)**:仅依赖词汇存在性与频次,不建模语序、语法或深层语义
---
## 二、完整打分公式
$$
\text{Score}(Q, D) = \sum_{i=1}^{n} \text{IDF}(q_i) \cdot \frac{(k_1 + 1) \cdot \text{tf}}{k_1 \cdot \left(1 - b + b \cdot \frac{dl}{\text{avgdl}} \right) + \text{tf}}
$$
| 符号 | 含义 |
|------|------|
| $ Q $ | 查询分词序列(经分词/过滤后) |
| $ D $ | 待评估文档 |
| $ \text{tf} $ | 查询词 $ q_i $ 在文档 $ D $ 中的出现频次 |
| $ dl $ | 文档 $ D $ 的总词项数(长度) |
| $ \text{avgdl} $ | 全量文档集合的平均长度 |
| $ \text{IDF}(q_i) $ | 查询词 $ q_i $ 的逆文档频率权重 |
| $ k_1 $ | 词频饱和系数(控制 tf 增长速率,默认 1.2~2.0) |
| $ b $ | 文档长度归一化系数(控制长度惩罚强度,默认 0.75) |
> 🔍 公式本质:对每个查询词独立打分后加总,每项由三部分耦合构成——**IDF 权重 × 饱和 TF × 长度归一化因子**
---
## 三、三大核心模块深度解析
### 1. IDF(逆文档频率)—— 判定“词有多重要”
$$
\text{IDF}(q_i) = \log \left( \frac{N - n + 0.5}{n + 0.5} + 1 \right)
$$
- $ N $:语料库中文档总数
- $ n $:包含该词的文档数量
✅ **冷门词 → $ n $ 小 → IDF 大 → 显著提分**
❌ **停用词(如“的”“是”“在”)→ $ n \approx N $ → IDF ≈ 0 → 几乎无贡献**
💡 *这是 BM25 抗噪能力的关键来源:天然过滤通用冗余词*
---
### 2. 饱和词频 TF —— BM25 的灵魂设计
对比传统 TF-IDF 的线性增长:
| 模型 | 词频影响趋势 | 极限行为 | 实际问题 |
|------|----------------|------------|-------------|
| TF-IDF | $ \text{TF} \propto \text{tf} $ | $ \text{tf} \to \infty $ ⇒ 分数 $ \to \infty $ | 关键词堆砌即可刷分;长文天然占优 |
| **BM25** | $ \displaystyle \frac{(k_1+1)\cdot\text{tf}}{k_1 + \text{tf}} $ | $ \text{tf} \to \infty $ ⇒ 分数 $ \to k_1 + 1 $ | 边际收益递减,杜绝作弊,保障内容质量优先 |
📌 当 $ k_1 = 1.2 $ 时,即使某词出现 10 次,其 TF 贡献也已接近上限(≈2.2),远低于线性模型下的 10 倍增幅。
---
### 3. 文档长度归一化 —— 实现长短文档公平竞技
$$
\text{LengthNorm} = 1 - b + b \cdot \frac{dl}{\text{avgdl}}
$$
| $ b $ 取值 | 行为解释 | 应用场景 |
|-------------|-----------|------------|
| $ b = 0 $ | 完全忽略文档长度差异 | 不推荐,退化为 TF-IDF |
| $ b = 1 $ | 严格按比例惩罚:$ dl > \text{avgdl} \Rightarrow \text{Norm} > 1 $,整体分数下降 | 过度压制长文,损失信息完整性 |
| **$ b = 0.75 $(ES 默认)** | 中庸稳健:适度抑制长文档膨胀分,同时保留合理表达空间 | 平衡精度与召回,适配通用搜索场景 |
> 📐 相同词频下,长文档分母变大 → 分数被压缩;短文档得分相对提升 → 真正“内容精炼者”胜出。
---
## 四、Elasticsearch 默认参数建议
| 参数 | 推荐值 | 设计意图 |
|------|---------|-----------|
| $ k_1 $ | `1.2` | 快速饱和,抑制关键词重复堆砌,强调内容多样性 |
| $ b $ | `0.75` | 中等强度长度归一化,兼顾新闻短文本与技术长文档的公平性 |
> 💡 这两个参数已在海量真实搜索日志中调优验证,可作为绝大多数业务的起点配置。
---
## 五、BM25 vs TF-IDF:关键维度对比表
| 特性 | TF-IDF | BM25 |
|------|--------|------|
| **词频增长方式** | 线性无限增长 | 饱和收敛,设上限 $ k_1 + 1 $ |
| **文档长度处理** | 无任何归一化,长文档天然高分 | 自动长度归一化,长短公平可比 |
| **抗作弊能力** | 弱:靠堆词/扩文即可提分 | 强:TF 饱和 + 长度抑制双重防护 |
| **理论基础** | 启发式统计经验公式 | 严格概率排序模型(基于二元独立概率假设) |
| **工业落地成熟度** | 曾广泛使用,现多用于基线或辅助特征 | 搜索引擎默认首选,毫秒级响应、高稳定性 |
---
## 六、一句话总结
> **BM25 = 稀有词高权重(IDF) + 词频边际递减(饱和 TF) + 长文档智能降权(LengthNorm)**
> 它不理解语义、不依赖上下文,却以极简统计逻辑达成极强鲁棒性与工程实用性,是现代搜索引擎与向量检索系统中**最可靠、最高效的前置召回打分标准**。
---
# 附录:TF-IDF 超通俗解析(对照理解 BM25 改进点)
## 1. 全称与定义
- **TF(Term Frequency)**:词频 → 某词在当前文档中出现的频率
- **IDF(Inverse Document Frequency)**:逆文档频率 → 全库中该词的“稀缺程度”
- **TF-IDF = TF × IDF**:综合局部显著性与全局判别力的加权指标
## 2. 核心原理一句话
> 一个词是否重要,取决于它:
> ✅ **在本文档里是否高频出现?**(TF)
> ✅ **在整个语料库里是否罕见?**(IDF)
> → 两者兼备,才是优质关键词!
## 3. 公式拆解
### ① TF(词频)
$$
\text{TF}(t,d) = \frac{\text{词 } t \text{ 在文档 } d \text{ 中出现次数}}{\text{文档 } d \text{ 的总词数}}
$$
- 文档越长、越易堆词 → TF 可被人为拉高
- ❗ 缺乏饱和约束 → 无法区分“有效强调”与“无效灌水”
### ② IDF(逆文档频率)
$$
\text{IDF}(t) = \log \frac{N}{n_t}
$$
(常用平滑形式:$ \log \frac{N+1}{n_t+1} + 1 $)
- “人工智能”仅见于 10 篇文章 → $ \text{IDF} \gg 0 $
- “我们”出现在全部 100 篇 → $ \text{IDF} \approx 0 $,自动失效
### ③ 最终权重
$$
\text{TF-IDF}(t,d) = \text{TF}(t,d) \times \text{IDF}(t)
$$
## 4. 大白话举例(100 篇文档库)
| 词 | 出现在多少篇? | IDF 级别 | 某文中出现次数 | TF-IDF 得分 |
|----|----------------|------------|------------------|----------------|
| 人工智能 | 10 篇 | ★★★★☆(高) | 10 次 | 高 → 核心关键词 |
| 我们 | 100 篇 | ☆☆☆☆☆(趋零) | 50 次 | 几乎为 0 → 噪声词 |
## 5. TF-IDF 的致命缺陷(正是 BM25 所解决的)
- ❌ **词频无上限**:出现 100 次 ≠ 比出现 10 次重要 10 倍;缺乏心理学/语言学依据
- ❌ **无视文档长度**:一篇万字综述 vs 一条百字摘要,在相同关键词频次下,前者必然碾压后者
- ❌ **易受攻击**:SEO 黑帽手段大量复制关键词即可伪造高相关性
## 6. TF-IDF ↔ BM25 终极对照
| 视角 | TF-IDF | BM25 |
|------|--------|------|
| **哲学定位** | 简单直观的经验公式 | 概率模型驱动的工业级优化方案 |
| **演进关系** | 原始基线 | 对 TF-IDF 的三大缺陷进行数学级修复 |
| **升级要点** | — | ✅ TF 饱和化 ✅ 长度归一化 ✅ IDF 平滑增强 |
| **适用阶段** | 教学入门 / 快速原型 | 生产环境 / 高并发搜索 / 多模态召回前置 |
