LangChain 专项训练 · Session 01
Q1
你先用自己的话说一下:LangChain 是什么?它主要解决什么问题?为什么很多 AI 应用开发会用它?
Q2
如果让你用 LangChain 搭一个最基础的问答应用,你会怎么描述它的核心组成?
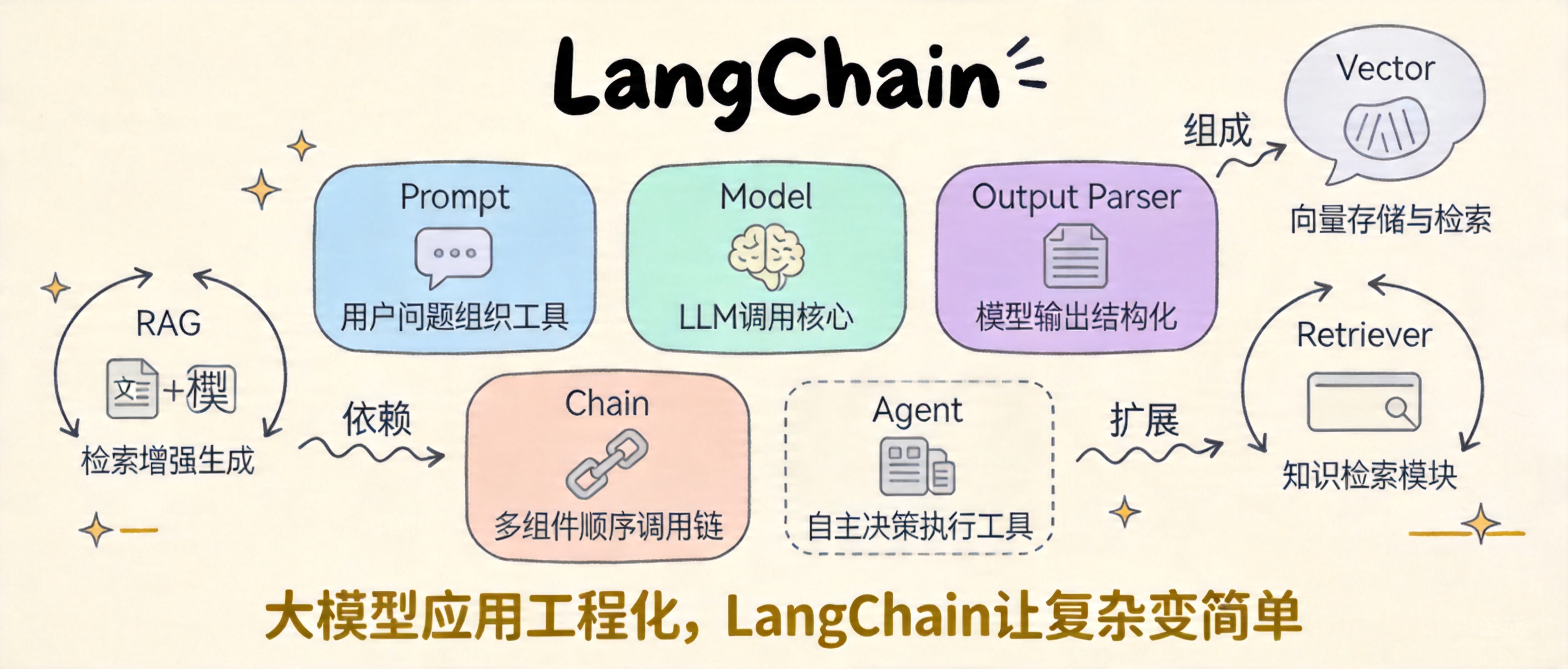
至少讲到这些概念:Prompt、Model、Output Parser、Chain。
Q3
Chain 的作用是什么?
为什么不直接手写一堆 Python 代码去调模型,而要用 LangChain 的链式组织方式?
Q4
如果你要做一个 RAG 问答系统,LangChain 在里面通常能帮你处理哪些环节?
Q5
Retriever 和 Vector Store 是什么关系?两者有什么区别?
Q6
如果面试官问你:LangChain 和 LangGraph 有什么区别?
你会怎么回答?
Q7
什么场景下你会考虑用 Agent,什么场景下你更愿意用固定 workflow/chain?
Q8
在 LangChain 里接工具时,你觉得最容易出问题的点是什么?
至少讲 3 个。
Q9
如果一个基于 LangChain 的应用回答不稳定,你会优先排查哪些地方?
Q10
如果你做了一个 LangChain 项目,面试官怀疑你只是“调库侠”,你怎么证明自己不只是会调用框架?
你直接按 Q1-Q10 回答。
这轮我会比刚才更严格,尤其看你是否能把 LangChain 和真实工程场景挂钩。
可以,下面直接给你一版 LangChain 专项训练标准答案,风格按面试口述来写,你可以直接背,也可以改成更像你自己的表达。
Q1
LangChain 本质上是一个大模型应用开发框架,用来把 Prompt、模型调用、知识检索、工具调用、记忆、工作流这些能力组织起来。它解决的问题不是“让模型更聪明”,而是让大模型应用更容易工程化搭建。很多 AI 应用开发会用它,是因为它把常见组件抽象好了,开发者可以更快搭建问答、RAG、Agent 和自动化流程,同时保留一定的可扩展性。
Q2
如果用 LangChain 搭一个最基础的问答应用,我会把它理解成几个核心组件。第一是 Prompt,负责把用户问题组织成模型更容易理解的输入;第二是 Model,也就是具体调用的 LLM;第三是 Output Parser,用来把模型输出整理成结构化结果,比如 JSON 或指定字段;第四是 Chain,用来把 Prompt、Model、Parser 串起来形成一个稳定可复用的调用链。这样做的好处是每一层职责比较清晰,后续好排查、好复用。
Q3
Chain 的作用是把多个步骤按固定顺序组织起来,让整个调用过程更清晰、更可维护。直接手写 Python 当然也能做,但当应用一旦变复杂,比如要做 Prompt 组装、模型调用、结果解析、异常处理、上下文拼接时,纯手写代码会越来越散。LangChain 的链式组织方式更适合把流程模块化,后续替换模型、调整 Prompt、增加中间步骤都更方便。它的价值不在于“少写几行代码”,而在于让大模型应用更容易工程化。
Q4
在 RAG 问答系统里,LangChain 通常可以帮助处理文档加载、文本切分、embedding、向量库接入、retriever 封装、重排前后的上下文拼接,以及最终的问答链路组织。它还可以把 Prompt 模板、检索器和模型调用组合成完整问答流程。换句话说,LangChain 更像是把 RAG 的各个模块串起来,让开发者更快完成原型和迭代。真正决定效果的,还是文档质量、切分策略、召回策略和 Prompt 设计。
Q5
Vector Store 是存储向量和相关文档片段的地方,比如 FAISS、Milvus、Chroma 这类组件;Retriever 是建立在数据存储之上的检索接口,它负责根据用户问题去取回相关内容。简单说,Vector Store 更偏底层存储和索引能力,Retriever 更偏上层检索能力。Retriever 不一定只基于向量库,也可以封装 BM25、混合检索或者带过滤条件的检索逻辑。
Q6
LangChain 更偏通用组件编排框架,适合搭建线性的链路,比如 Prompt、模型、检索、工具这些模块的组合;LangGraph 更偏有状态、多步骤、可循环、可分支的工作流编排,尤其适合复杂 Agent 场景。简单理解,LangChain 更适合普通 AI 应用和固定流程,LangGraph 更适合多轮决策、状态流转、任务规划、失败重试这类复杂流程。很多场景不是二选一,而是 LangChain 负责基础组件,LangGraph 负责更复杂的工作流控制。
Q7
如果任务流程比较固定,输入输出明确,比如知识库问答、报告生成、固定信息抽取,我更愿意用固定 workflow 或 chain,因为它更稳定、可控、也更容易测试。如果任务中存在动态决策,比如要根据问题内容决定查哪个系统、调用哪个工具、是否继续追问用户,那我才会考虑 Agent。简单说,能用固定流程解决的问题,尽量不要上 Agent;只有在步骤不固定、工具选择动态变化时,Agent 才更有价值。
Q8
LangChain 接工具时最容易出问题的点,我觉得至少有三个。第一是工具描述不清,导致模型不知道什么时候该调用、调用哪个工具;第二是输入参数设计不规范,模型生成的参数格式不稳定,容易调用失败;第三是错误处理和兜底不足,比如接口超时、返回空值、字段缺失时没有处理好。再补一个常见问题,就是工具太多但没有清晰边界,模型会乱选工具,导致整体效果很飘。
Q9
如果一个基于 LangChain 的应用回答不稳定,我会优先从四层排查。第一层看 Prompt 是否稳定,约束是不是太弱;第二层看检索链路,包括切分、召回、top-k、重排和上下文拼接;第三层看工具调用是否有失败、参数错误或返回异常;第四层再看模型本身,比如温度参数、上下文长度和输出解析方式。很多所谓“模型不稳定”,其实本质上是上游输入和流程不稳定。
Q10
如果面试官怀疑我只是调库,我会强调两点。第一,框架只是组织方式,真正决定效果的是我怎么做 Prompt 设计、检索策略、工具 schema、异常处理、日志监控和效果评估;第二,我会结合项目讲具体取舍,比如为什么某个场景不用 Agent 而用固定 workflow,为什么要做混合检索,为什么某些表格数据不走 RAG 而走 SQL。能把这些设计判断和问题排查讲清楚,基本就能说明我不是单纯调库,而是真的理解大模型应用的工程实现。
