这一组按真实面试标准看,整体大概 61/100。方向没跑偏,但答案普遍过短,很多点只说了“关键词”,没有展开成“面试官能信服的工程表达”。如果这是正式一面,你会被连续追问。
逐题点评
Q1 评分:12/20
你的回答抓到了 3 个核心点:私域知识补充、知识时效性、降低幻觉,这是对的。
问题是你把 RAG 说成了“索引增强”,更标准的说法应该是 检索增强生成(Retrieval-Augmented Generation)。另外你没有讲清楚它的本质不是“替代模型知识”,而是“在生成前先检索外部可信上下文,再让模型基于上下文回答”。
更优表达应该是:
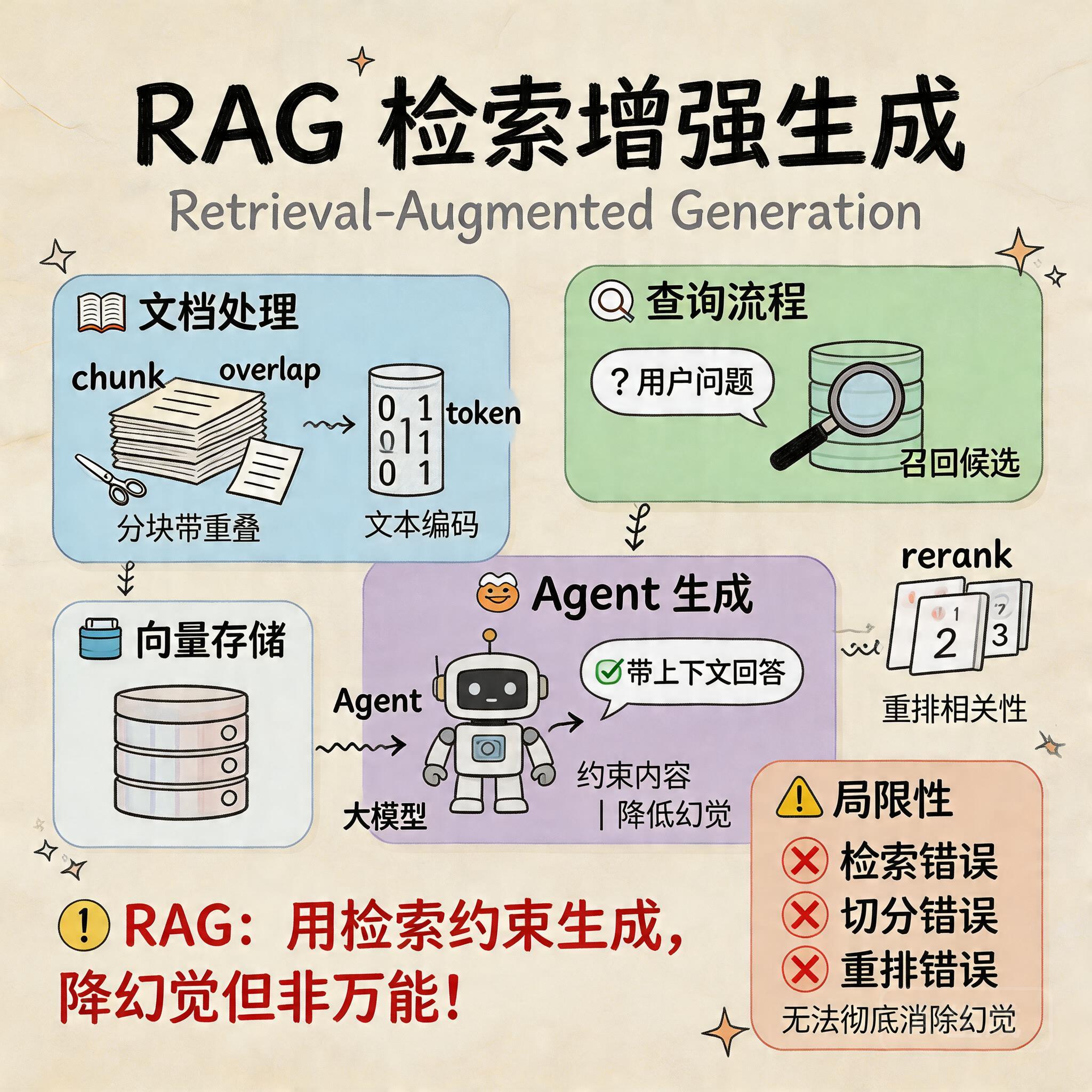
RAG 是一种让大模型在回答前,先从外部知识库检索相关内容,再把检索结果作为上下文输入给模型生成答案的方案。它主要解决三个问题:一是模型参数内知识不覆盖企业私域数据;二是模型知识有时间截断,无法天然知道最新文档;三是直接裸问模型容易幻觉,RAG 可以把回答约束在可追溯的资料范围内。企业里常用于知识库问答、客服助手、运维手册查询、制度流程问答等场景。
面试官可能追问你:
RAG 能不能彻底解决幻觉?
更好回答:不能彻底解决,只能显著降低。因为检索错、切分错、重排错,或者模型对检索内容理解错,仍然会产生错误答案。
Q2 评分:13/20
你把主链路说出来了:解析 -> 切分 -> embedding -> 存储 -> 查询 -> 召回 -> rerank -> 生成,这是合格线以上。
但问题很明显:你没有讲存储层、索引层、元数据,也没有讲“引用返回”和“权限过滤”,工程味不够。python-doc库 这个说法也不严谨,一般说 python-docx / PDF 解析器 / OCR / Unstructured 之类。
更优答案可以这么说:
完整链路一般分为离线建库和在线问答两部分。离线阶段先做文档接入,包括 PDF、Word、网页、Excel 等解析,然后做清洗、去噪、标题层级识别和元数据抽取;接着按段落、标题或 token 长度做 chunk 切分,并保留文档名、页码、标题、时间等 metadata;之后用 embedding 模型把 chunk 向量化,写入向量库,同时可建立 BM25 倒排索引用于关键词检索。在线阶段用户提问后,先做 query 改写或规范化,然后走向量召回和关键词召回,再做 rerank,取 top-k 片段连同引用信息一起拼进 prompt,让 LLM 基于证据生成答案,并返回出处、页码或原文片段。
你这题最容易被追问的是:
为什么 metadata 很重要?
答案:因为它决定了过滤能力和可解释性,比如按文档类型、时间、部门、权限、设备编号过滤,同时还能给最终答案返回引用来源。
Q3 评分:11/20
你的方向是对的,但答得太单薄。只提到“编号、关键词”还不够,面试官会觉得你只是听过这个词。
更完整的答法:
纯向量检索的优点是能处理语义相似问题,比如用户和文档表述不一致时,仍然可能召回相关内容。但它对精确关键词不敏感,尤其是设备编号、报错代码、接口名、制度编号、人名地名、英文缩写这类 token,语义空间里未必稳定,所以可能漏召。BM25 或关键词检索擅长精确匹配字面词,能补向量检索在专有名词和稀疏词上的不足。混合检索就是把语义召回和关键词召回结合起来,再统一 rerank,提高召回覆盖率和最终命中率。
面试官追问常见是:
那你怎么融合两路召回结果?
你可以答:常见做法是分别取 topN 后合并去重,再用 reranker 做统一排序;也可以做加权分数融合,但最终通常还是需要重排模型做最后判定。
Q4 评分:11/20
你答到了核心:chunk 大有噪声,chunk 小会丢上下文。但你把“语义缺失”说成了“语音缺失”,正式面试里要注意口误。
另外这题最好再补两个点:召回粒度 和 生成阶段上下文利用率。
更优答案:
chunk 切分直接影响召回和生成质量。chunk 太大时,一个片段里可能混入多个主题,召回虽然命中,但有效信息密度低,会把很多无关内容带进 prompt,增加噪声和 token 成本;chunk 太小时,上下文被切碎,模型拿到的只是零散句子,容易缺主语、缺条件、缺结论,导致回答不完整。实际工程里通常会根据文档结构做分层切分,比如标题+段落优先,再结合 token 长度控制,并加 overlap,尽量兼顾语义完整性和检索精度。
常见追问:
overlap 为什么需要?
答案:因为很多关键信息跨段分布,适度 overlap 可以降低边界切断带来的信息损失。
Q5 评分:14/20
这题你的判断是对的:必须结合 Agent / function calling。
但答案太短,没有讲清楚为什么“纯 RAG 不够”。真正打动面试官的是你要把这个问题拆成“文档知识”和“实时数据”两类。
更优答案:
这个场景不能只靠纯 RAG,因为问题里既有知识解释需求,也有实时数据分析需求。RAG 适合回答空压机的原理、常见异常原因、历史维修规范、告警含义等文档型知识;但“最近 7 天为什么能耗异常”本质上需要读取实时或近实时业务数据,比如设备能耗曲线、运行时长、负载率、告警记录、产量数据、维护记录等,所以必须结合工具调用或 Agent Workflow 去查 EMS/IoT/告警系统接口。更合理的方案是:先用工具拉取近 7 天数据,再结合知识库中的设备说明、阈值规则、历史案例,让模型生成分析结论和排查建议。
这里面试官大概率会追问:
为什么一定要 Agent,普通后端接口拼接不行吗?
回答:如果链路固定、输入输出明确,普通后端编排也可以;只有当任务存在动态决策、多工具选择、步骤依赖时,Agent 才更有价值。
你这一轮的主要问题
你知道概念,但还没有把答案说成“工程化表达”。
回答过短,很多地方像提纲,不像口述。
缺少术语精度,比如 检索增强生成、metadata、hybrid retrieval、rerank、引用返回、权限过滤。
没有主动补“局限性”和“取舍”,而这正是中高级面试官很爱听的。
你现在最该背的答题模板
你以后答 RAG 题,尽量套这个 4 段式:
先定义
先一句话定义它是什么。
再讲问题
它解决什么问题,为什么不是裸用大模型。
再讲链路
离线建库怎么做,在线问答怎么做。
最后讲边界
它的局限、什么时候要接工具、什么时候要混合检索。
给你一版更像面试口述的 Q1-Q5 压缩示范
Q1 简版示范
RAG 就是检索增强生成,核心是在大模型回答前,先从外部知识库里检索相关内容,再把这些内容作为上下文交给模型生成答案。它主要解决企业私域知识不在模型参数里、模型知识有时间截断,以及裸问模型容易幻觉的问题。企业里很常见,因为制度文档、产品手册、FAQ、运维知识都适合这种模式。
Q2 简版示范
完整链路一般分两部分。离线阶段先做文档接入和解析,再清洗、切分、抽 metadata、做 embedding,写入向量库,必要时还会建关键词索引。在线阶段用户提问后,先做 query 规范化,再召回、重排,把最相关片段和引用一起放进 prompt,让 LLM 基于证据回答,最后把答案和出处一起返回。
Q3 简版示范
因为纯向量检索更擅长语义相似,但对设备编号、错误码、制度编号、接口名这类精确词不稳定,容易漏召。关键词检索正好补这一块。实际工程里通常会把向量检索和 BM25 混合,再统一 rerank。
Q4 简版示范
chunk 太大,主题容易混杂,召回噪声高,还浪费上下文窗口;chunk 太小,语义上下文不完整,模型拿到的信息碎片化,回答容易缺条件和结论。一般会结合标题层级、段落结构、token 长度和 overlap 一起设计。
Q5 简版示范
这个场景不能只靠纯 RAG,因为它不仅要解释知识,还要分析最近 7 天的实时业务数据。RAG 可以提供设备说明、告警规则、排查手册,但实时能耗、运行状态、维修记录这些必须通过工具调用查接口。更合理的是 RAG + function calling 或工作流编排。
